For at imødekomme behovene hos cloud-tjenester er netværket gradvist opdelt i Underlay og Overlay. Underlay-netværket er det fysiske udstyr såsom routing og switching i traditionelle datacentre, der stadig tror på stabilitet og leverer pålidelige netværksdatatransmissionsmuligheder. Overlay er det forretningsnetværk, der er indkapslet på det, tættere på tjenesten, gennem VXLAN- eller GRE-protokolindkapsling, for at give brugerne brugervenlige netværkstjenester. Underlay-netværk og Ooverlay-netværk er relaterede og afkoblede, og de er relateret til hinanden og kan udvikle sig uafhængigt.
Underlay-netværket er fundamentet for netværket. Hvis underlay-netværket er ustabilt, er der ingen SLA for virksomheden. Efter trelags-netværksarkitekturen og Fat-Tree-netværksarkitekturen overgår datacenternetværksarkitekturen til Spine-Leaf-arkitekturen, hvilket indvarslede den tredje anvendelse af CLOS-netværksmodellen.
Traditionel datacenternetværksarkitektur
Trelagsdesign
Fra 2004 til 2007 var trelags netværksarkitekturen meget populær i datacentre. Den har tre lag: kernelaget (netværkets højhastigheds-switching-rygrad), aggregeringslaget (som leverer politikbaseret forbindelse) og adgangslaget (som forbinder arbejdsstationer til netværket). Modellen er som følger:
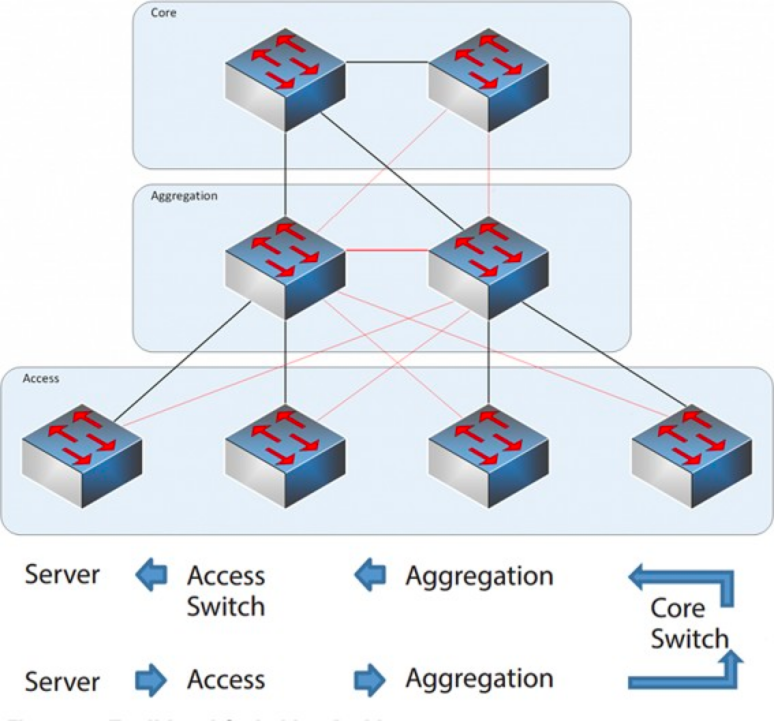
Trelags netværksarkitektur
Kernelag: Kerneswitchene giver højhastighedsvideresendelse af pakker ind og ud af datacentret, forbindelse til de flere aggregeringslag og et robust L3-routingnetværk, der typisk betjener hele netværket.
Aggregationslag: Aggregationsswitchen opretter forbindelse til adgangsswitchen og leverer andre tjenester, såsom firewall, SSL-offload, indtrængningsdetektion, netværksanalyse osv.
Adgangslag: Adgangsswitchene er normalt øverst i racket, så de kaldes også ToR (Top of Rack) switche, og de opretter fysisk forbindelse til serverne.
Typisk er aggregeringsswitchen afgrænsningspunktet mellem L2- og L3-netværk: L2-netværket er under aggregeringsswitchen, og L3-netværket er ovenover. Hver gruppe af aggregeringsswitche administrerer et leveringspunkt (POD), og hver POD er et uafhængigt VLAN-netværk.
Netværksløjfe og Spanning Tree-protokol
Dannelsen af loops skyldes oftest forvirring på grund af uklare destinationsstier. Når brugere bygger netværk, bruger de normalt redundante enheder og redundante links for at sikre pålidelighed, så der uundgåeligt dannes loops. Lag 2-netværket er i det samme broadcast-domæne, og broadcast-pakkerne vil blive transmitteret gentagne gange i loopen, hvilket danner en broadcast-storm, som kan forårsage portblokering og udstyrslammelse på et øjeblik. Derfor er det nødvendigt at forhindre dannelsen af loops for at forhindre broadcast-storms.
For at forhindre dannelsen af loops og for at sikre pålidelighed er det kun muligt at omdanne redundante enheder og redundante links til backup-enheder og backup-links. Det vil sige, at redundante enheds-porte og links blokeres under normale omstændigheder og ikke deltager i videresendelsen af datapakker. Kun når den nuværende videresendelsesenhed, port eller link fejler, hvilket resulterer i netværksbelastning, åbnes redundante enheds-porte og links, så netværket kan gendannes til normal. Denne automatiske kontrol implementeres af Spanning Tree Protocol (STP).
Spanning tree-protokollen fungerer mellem adgangslaget og sinklaget, og i kernen er der en spanning tree-algoritme, der kører på hver STP-aktiveret bro. Algoritmen er specifikt designet til at undgå bro-løkker i tilfælde af redundante stier. STP vælger den bedste datasti til videresendelse af beskeder og udelukker de links, der ikke er en del af spanning tree-protokollen, hvilket efterlader kun én aktiv sti mellem to netværksnoder, og den anden uplink vil blive blokeret.
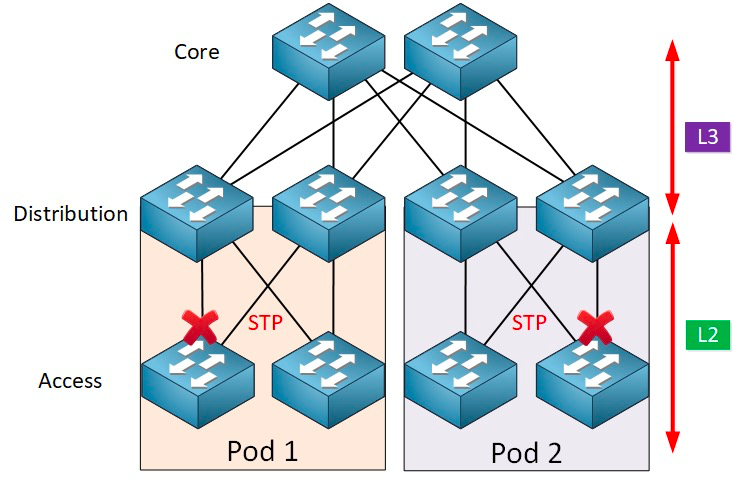
STP har mange fordele: det er simpelt, plug-and-play og kræver meget lidt konfiguration. Maskinerne i hver pod tilhører det samme VLAN, så serveren kan migrere placeringen vilkårligt inden for pod'en uden at ændre IP-adressen og gatewayen.
Parallelle videresendelsesstier kan dog ikke bruges af STP, som altid vil deaktivere redundante stier inden for VLAN'et. Ulemper ved STP:
1. Langsom konvergens af topologi. Når netværkstopologien ændres, tager det spanning tree-protokollen 50-52 sekunder at fuldføre topologikonvergensen.
2, kan ikke fungere som load balancing. Når der er en løkke i netværket, kan spanning tree-protokollen blot blokere løkken, så linket ikke kan videresende datapakker, hvilket spilder netværksressourcer.
Virtualisering og udfordringer med øst-vest-trafik
Efter 2010 begyndte datacentre at anvende virtualiseringsteknologi for at forbedre udnyttelsen af computer- og lagringsressourcer, og et stort antal virtuelle maskiner begyndte at dukke op i netværket. Virtuel teknologi omdanner en server til flere logiske servere, hvor hver VM kan køre uafhængigt, har sit eget operativsystem, APP, sin egen uafhængige MAC-adresse og IP-adresse, og de opretter forbindelse til den eksterne enhed via den virtuelle switch (vSwitch) inde i serveren.
Virtualisering har et ledsagende krav: live-migrering af virtuelle maskiner, muligheden for at flytte et system af virtuelle maskiner fra én fysisk server til en anden, samtidig med at den normale drift af tjenester på de virtuelle maskiner opretholdes. Denne proces er ufølsom over for slutbrugere, administratorer kan fleksibelt allokere serverressourcer eller reparere og opgradere fysiske servere uden at påvirke brugernes normale brug.
For at sikre, at tjenesten ikke afbrydes under migreringen, kræves det, at ikke blot den virtuelle maskines IP-adresse forbliver uændret, men også at den virtuelle maskines driftstilstand (f.eks. TCP-sessionstilstanden) opretholdes under migreringen, så den dynamiske migrering af den virtuelle maskine kun kan udføres i det samme lag 2-domæne, men ikke på tværs af lag 2-domænemigreringen. Dette skaber behov for større L2-domæner fra adgangslaget til kernelaget.
Skillepunktet mellem L2 og L3 i den traditionelle store layer 2-netværksarkitektur er ved core-switchen, og datacenteret under core-switchen er et komplet broadcast-domæne, det vil sige L2-netværket. På denne måde kan den realisere vilkårligheden af enhedsimplementering og placeringsmigrering, uden at det er nødvendigt at ændre konfigurationen af IP og gateway. De forskellige L2-netværk (VLans) routes gennem core-switchene. Core-switchen under denne arkitektur skal dog opretholde en enorm MAC- og ARP-tabel, hvilket stiller høje krav til core-switchens ydeevne. Derudover begrænser Access Switch (TOR) også skalaen af hele netværket. Disse begrænser i sidste ende netværkets skala, netværksudvidelse og elasticitetsevne, forsinkelsesproblemet på tværs af de tre planlægningslag, hvilket ikke kan opfylde fremtidige forretningsbehov.
På den anden side bringer den øst-vest-gående trafik, som virtualiseringsteknologi medfører, også udfordringer for det traditionelle trelagsnetværk. Datacentertrafik kan bredt opdeles i følgende kategorier:
Nord-syd trafik:Trafik mellem klienter uden for datacentret og datacenterserveren, eller trafik fra datacenterserveren til internettet.
Øst-vest trafik:Trafik mellem servere i et datacenter, samt trafik mellem forskellige datacentre, såsom disaster recovery mellem datacentre, kommunikation mellem private og offentlige clouds.
Introduktionen af virtualiseringsteknologi gør udrulningen af applikationer mere og mere distribueret, og "bivirkningen" er, at øst-vest-trafikken stiger.
Traditionelle trelagsarkitekturer er typisk designet til nord-syd-trafik.Selvom den kan bruges til øst-vest-trafik, kan den i sidste ende ikke fungere som krævet.
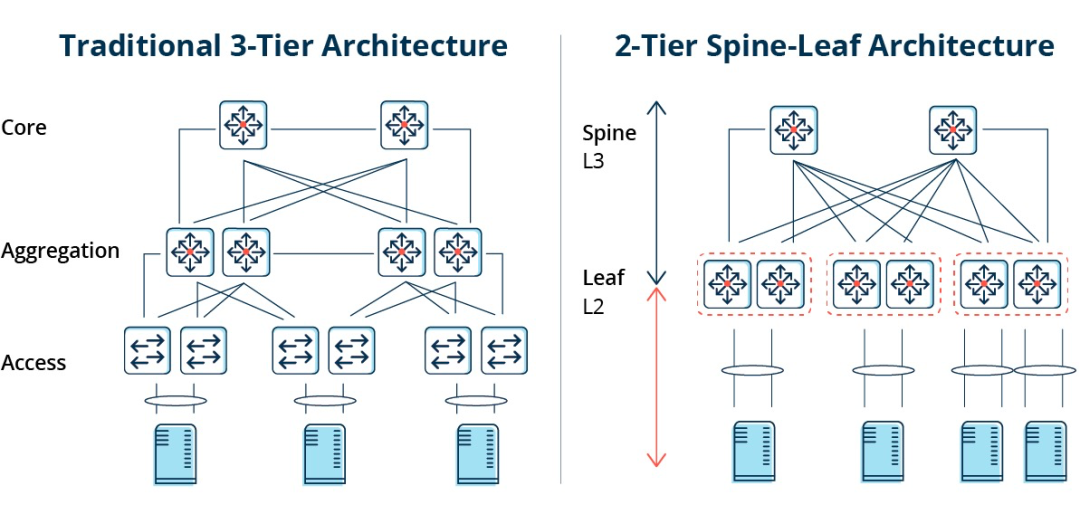
Traditionel trelagsarkitektur vs. Spine-Leaf-arkitektur
I en trelagsarkitektur skal øst-vest-trafik videresendes via enheder i aggregerings- og kernelagene. Den passerer unødvendigt gennem mange noder. (Server -> Adgang -> Aggregering -> Kerne-switch -> Aggregering -> Adgangsswitch -> Server)
Hvis en stor mængde øst-vest-trafik kører gennem en traditionel trelags netværksarkitektur, kan enheder, der er tilsluttet den samme switchport, derfor konkurrere om båndbredde, hvilket resulterer i dårlige svartider for slutbrugerne.
Ulemper ved traditionel trelags netværksarkitektur
Det kan ses, at den traditionelle trelags netværksarkitektur har mange mangler:
Båndbreddespild:For at forhindre looping køres STP-protokollen normalt mellem aggregeringslaget og adgangslaget, så kun én uplink på adgangsswitchen reelt bærer trafik, og de andre uplinks blokeres, hvilket resulterer i spild af båndbredde.
Vanskeligheder ved placering af store netværk:Med udvidelsen af netværksskalaen er datacentre fordelt på forskellige geografiske steder, virtuelle maskiner skal oprettes og migreres overalt, og deres netværksattributter såsom IP-adresser og gateways forbliver uændrede, hvilket kræver understøttelse af Fat Layer 2. I den traditionelle struktur kan der ikke udføres nogen migrering.
Mangel på øst-vest trafik:Trelagsnetværksarkitekturen er primært designet til nord-syd-trafik, selvom den også understøtter øst-vest-trafik, men manglerne er åbenlyse. Når øst-vest-trafikken er stor, vil presset på aggregeringslaget og kernelagets switche øges kraftigt, og netværkets størrelse og ydeevne vil være begrænset til aggregeringslaget og kernelaget.
Dette sætter virksomheder i dilemmaet mellem omkostninger og skalerbarhed:Understøttelse af store højtydende netværk kræver et stort antal konvergenslags- og kernelagsudstyr, hvilket ikke kun medfører høje omkostninger for virksomheder, men også kræver, at netværket planlægges på forhånd, når netværket bygges. Når netværksskalaen er lille, vil det forårsage spild af ressourcer, og når netværksskalaen fortsætter med at udvide, er det vanskeligt at udvide.
Rygradsbladnetværksarkitekturen
Hvad er Spine-Leaf-netværksarkitekturen?
Som svar på ovenstående problemer,Et nyt datacenterdesign, Spine-Leaf-netværksarkitektur, er dukket op, hvilket vi kalder et leaf ridge-netværk.
Som navnet antyder, har arkitekturen et ryglag og et bladlag, inklusive rygsøjle- og bladknap-knapper.
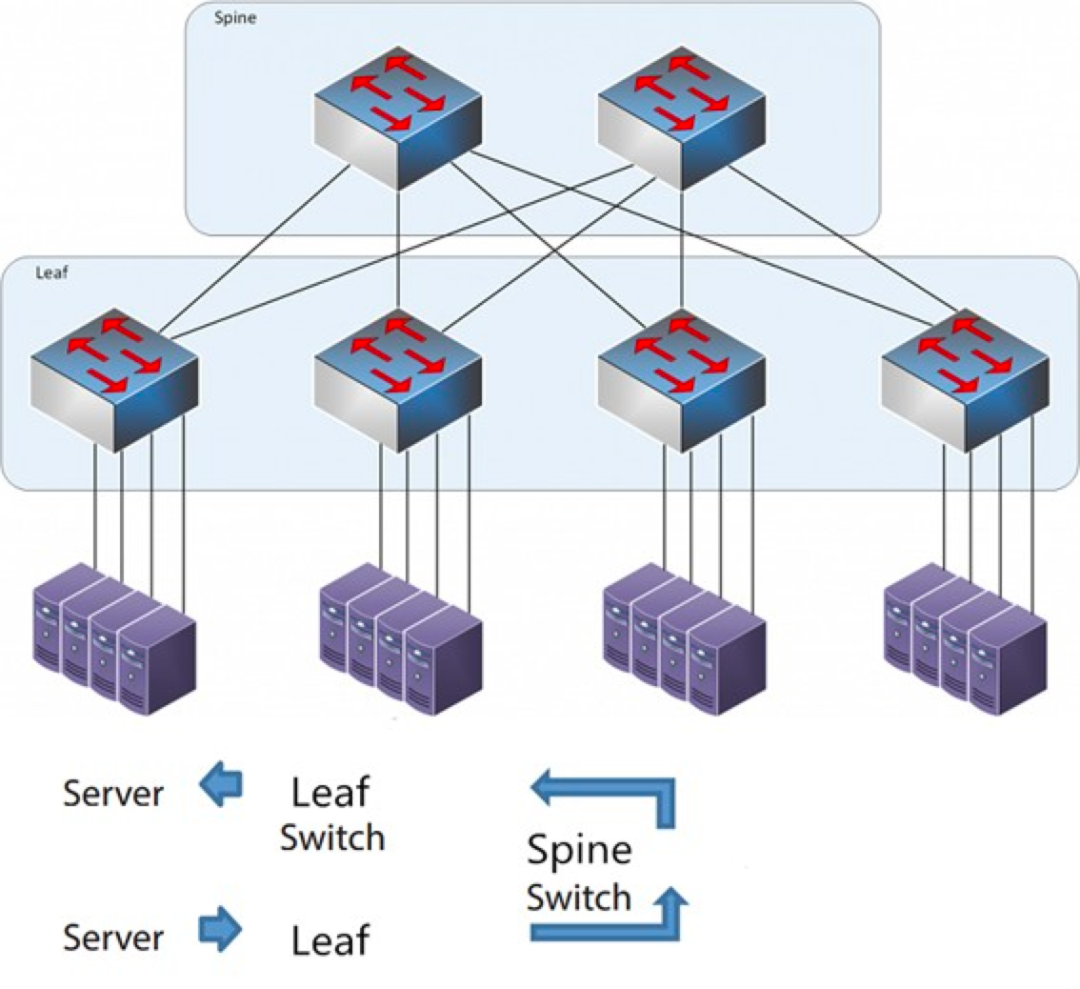
Rygbladsarkitekturen
Hver bladkontakt er forbundet til alle rygkontakterne, som ikke er direkte forbundet med hinanden, og danner en full-mesh-topologi.
I spine-and-leaf-systemet går en forbindelse fra én server til en anden gennem det samme antal enheder (Server -> Leaf -> Spine Switch -> Leaf Switch -> Server), hvilket sikrer forudsigelig latenstid. Fordi en pakke kun behøver at gå gennem én spine og et andet leaf for at nå destinationen.
Hvordan fungerer Spine-Leaf?
Leaf Switch: Den svarer til adgangsswitchen i den traditionelle trelagsarkitektur og forbinder direkte til den fysiske server som TOR (Top Of Rack). Forskellen med adgangsswitchen er, at afgrænsningspunktet for L2/L3-netværket nu er på Leaf-switchen. Leaf-switchen er placeret over 3-lagsnetværket, og Leaf-switchen er placeret under det uafhængige L2-broadcastdomæne, hvilket løser BUM-problemet i det store 2-lagsnetværk. Hvis to Leaf-servere skal kommunikere, skal de bruge L3-routing og videresende det via en Spine-switch.
Spine Switch: Svarende til en core switch. ECMP (Equal Cost Multi Path) bruges til dynamisk at vælge flere stier mellem Spine- og Leaf-switchene. Forskellen er, at Spine nu blot leverer et robust L3-routingnetværk til Leaf-switchen, så datacentrets nord-syd-trafik kan dirigeres fra Spine-switchen i stedet for direkte. Nord-syd-trafik kan dirigeres fra edge-switchen parallelt med Leaf-switchen til WAN-routeren.
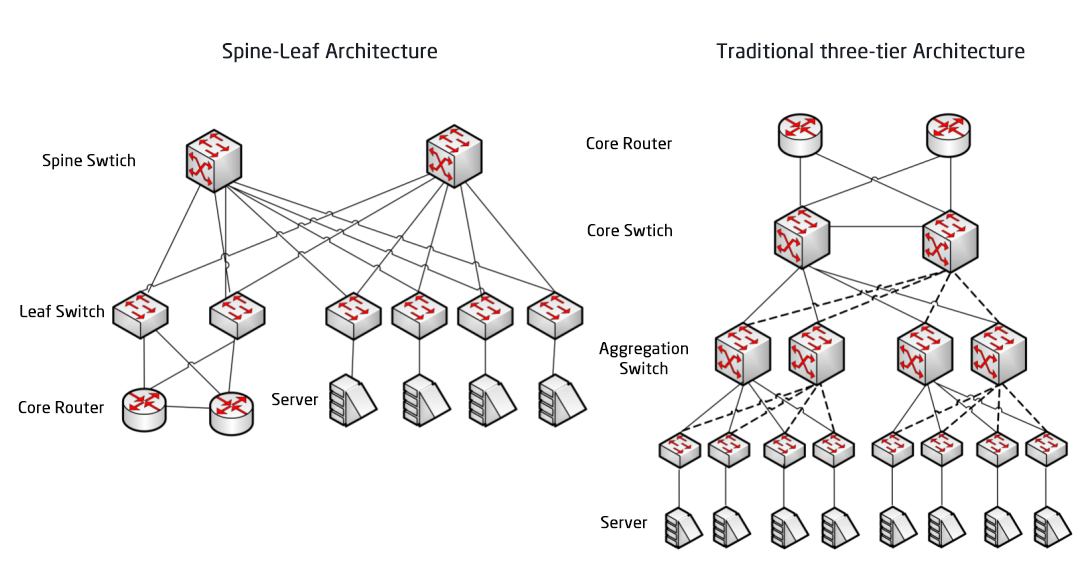
Sammenligning mellem Spine/Leaf-netværksarkitektur og traditionel trelags netværksarkitektur
Fordele ved rygblad
Flad:Et fladt design forkorter kommunikationsvejen mellem servere, hvilket resulterer i lavere latenstid, hvilket kan forbedre applikations- og tjenesteydelsen betydeligt.
God skalerbarhed:Når båndbredden er utilstrækkelig, kan en forøgelse af antallet af ridge-switche forlænge båndbredden horisontalt. Når antallet af servere stiger, kan vi tilføje leaf-switche, hvis porttætheden er utilstrækkelig.
Omkostningsreduktion: Nordgående og sydgående trafik, enten udgående fra bladknuder eller udgående fra højderygknuder. Øst-vest-strøm, fordelt over flere stier. På denne måde kan bladkamnetværket bruge faste konfigurationsswitche uden behov for dyre modulære switche og dermed reducere omkostningerne.
Lav latenstid og undgåelse af overbelastning:Datastrømme i et Leaf ridge-netværk har det samme antal hop på tværs af netværket uanset kilde og destination, og to servere kan nås fra hinanden via tre hop. Dette etablerer en mere direkte trafiksti, hvilket forbedrer ydeevnen og reducerer flaskehalse.
Høj sikkerhed og tilgængelighed:STP-protokollen bruges i den traditionelle trelags netværksarkitektur, og når en enhed fejler, vil den konvergere igen, hvilket påvirker netværkets ydeevne eller endda svigter. I leaf-ridge-arkitekturen er der ikke behov for at konvergere igen, når en enhed fejler, og trafikken fortsætter med at passere gennem andre normale stier. Netværksforbindelsen påvirkes ikke, og båndbredden reduceres kun med én sti, med lille indflydelse på ydeevnen.
Load balancing via ECMP er velegnet til miljøer, hvor centraliserede netværksstyringsplatforme som SDN anvendes. SDN gør det muligt at forenkle konfiguration, styring og omdirigering af trafik i tilfælde af blokering eller linkfejl, hvilket gør den intelligente load balancing full mesh-topologi til en relativt enkel måde at konfigurere og administrere.
Spine-Leaf-arkitekturen har dog nogle begrænsninger:
En ulempe er, at antallet af switche øger netværkets størrelse. Datacentret i Leaf Ridge-netværksarkitekturen skal øge antallet af switche og netværksudstyr proportionalt med antallet af klienter. Efterhånden som antallet af værter stiger, er der behov for et stort antal Leaf-switche for at uplinke til Ridge-switchen.
Den direkte sammenkobling af kip- og kipkontakter kræver matchning, og generelt kan det rimelige båndbreddeforhold mellem kip- og kipkontakter ikke overstige 3:1.
For eksempel er der 48 klienter med en hastighed på 10 Gbps på leaf-switchen med en samlet portkapacitet på 480 Gb/s. Hvis de fire 40G uplink-porte på hver leaf-switch er forbundet til 40G ridge-switchen, vil den have en uplink-kapacitet på 160 Gb/s. Forholdet er 480:160 eller 3:1. Datacenter-uplinks er typisk 40G eller 100G og kan migreres over tid fra et startpunkt på 40G (Nx 40G) til 100G (Nx 100G). Det er vigtigt at bemærke, at uplinket altid skal køre hurtigere end downlinket for ikke at blokere portlinket.
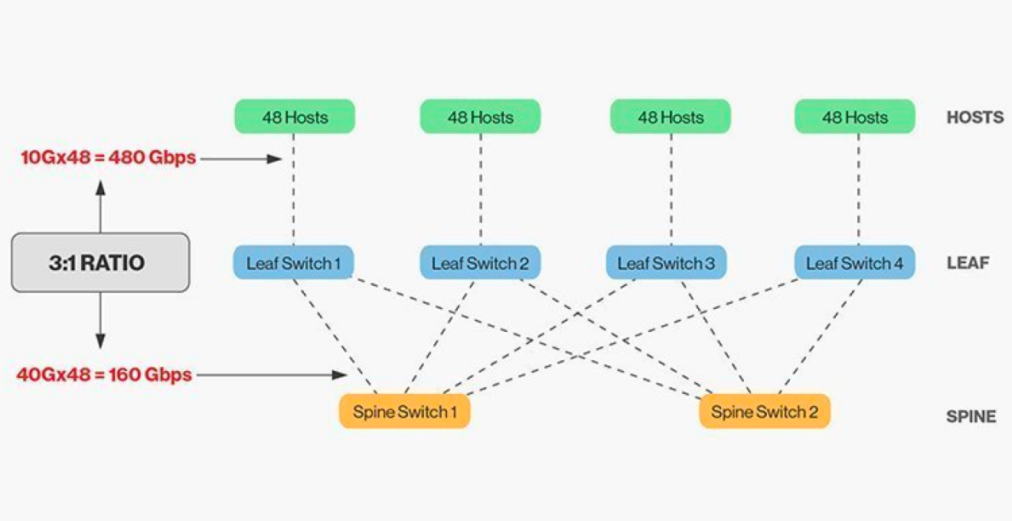
Spine-Leaf-netværk har også klare krav til ledningsføring. Fordi hver leaf-node skal være forbundet til hver spine-switch, er vi nødt til at lægge flere kobber- eller fiberoptiske kabler. Afstanden mellem forbindelsen øger omkostningerne. Afhængigt af afstanden mellem de sammenkoblede switche er antallet af avancerede optiske moduler, der kræves af Spine-Leaf-arkitekturen, titalls gange højere end antallet af traditionelle trelagsarkitekturer, hvilket øger de samlede implementeringsomkostninger. Dette har dog ført til vækst på markedet for optiske moduler, især for højhastighedsoptiske moduler såsom 100G og 400G.
Opslagstidspunkt: 26. januar 2026



